The $100,000 Chatbot
Our under-patent platform, Augmen.IO "Sentia", can drive a 90% reduction in costs for stateful AI, while simultaneously improving throughput by 2-3x and reducing latency by up to 50%. This isn't a trade-off; it's the result of a architecture designed for the real-world needs of the banking and financial services industry. While the common approach relies on expensive, slow, and inefficient semantic search across massive vector databases, we focused on a structured data model that delivers unparalleled performance and cost-efficiency. We’ve published a full, detailed analysis comparing these two architectures head-to-head for a 1-million-user banking scenario. Don't over-invest in an inefficient model. Read our deep-dive to understand how to build smarter, faster, and more profitable AI.
Augmen
8/12/2025
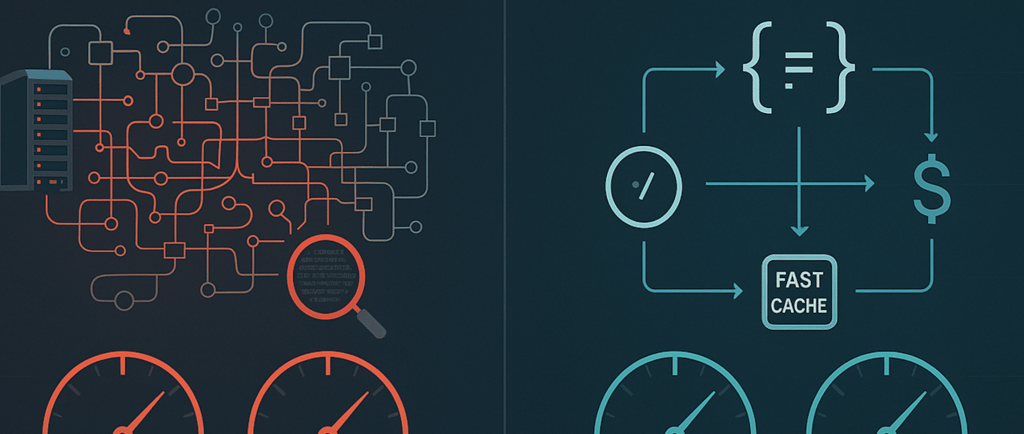
Every bank is rushing to deploy an AI chatbot. The promise is incredible: 24/7 personalized service, instant answers, and deeper customer relationships. But a universal frustration is setting in. You ask the chatbot for your balance, then ask, “What was my last transaction?” and it replies, “I’m sorry, I don’t have access to your previous questions.” The AI has no memory.
This is because building a stateful AI—one that remembers you—is an immense technical and financial challenge. The common industry approach, while powerful, is leading institutions down a path of astronomical costs and sluggish performance. But there is a better way.
This article dissects two architectural models for building a banking AI with memory. We’ll use a real-world cost analysis for supporting one million customers, showing how a return to first principles in software design can deliver a solution that is not only 10x cheaper but significantly faster.
The Standard Approach: MCP and the Vector Database Memory
Let’s imagine a typical conversation. A customer wants to understand their spending.
You: “What’s my checking account balance?”
AI: “Your balance is ₹85,000.”
You: “Okay, and what was that large purchase I made last month?”
To answer this last question, the AI needs memory. The standard approach, often using protocols like MCP (Model Context Protocol), tackles this with a brute-force semantic search strategy.
How it Works (In Detail):
Store Everything: Every conversation transcript is stored as unstructured text in a specialized vector database (like Pinecone or a large ChromaDB cluster). For 1 million customers, this becomes a massive, multi-billion vector index.
Semantic Search: When you ask about the "large purchase," the system doesn't understand "purchase." Instead, it converts your question into a vector (a numeric representation of its meaning).
Find Similar Chunks: It then searches the entire billion-vector database to find chunks of past conversations that are semantically similar to your question.
Prompt Stuffing: It retrieves the most relevant text snippets (e.g., “...your transaction on July 15th to ‘Electronics Store’ for ₹45,000…”) and stuffs them into a large prompt for the LLM (like Gemini).
Final Answer: The LLM reads this context and finally generates the answer.
This approach is powerful for searching unstructured documents, but it comes with immense risks and costs. The underlying MCP standard has been criticized for lacking built-in security, observability, and versioning, forcing companies to rely on a fragmented ecosystem of third-party tools.
The Sobering Cost Analysis
This architecture is incredibly expensive. The primary cost isn't the AI model; it's the high fixed cost of keeping a massive vector index "hot" and ready in a high-performance, managed database 24/7.
Here are the estimated monthly costs for this single-cluster vector DB model, storing data for 1 million users.
(For ultimate security, a Physically Separated model would cost over $80,000 / ₹67 Lakh per month due to massive engineering overhead, making it non-viable for most.)
The Alternative: The Sentia Structured Data Approach
What if we treat memory not as a search problem, but as a structured data problem? This is the Sentia philosophy. Instead of a messy transcript, a customer’s memory is a clean, organized JSON object containing around 500 key data points.
How it Works (The Same Banking Scenario):
Slot Filling: As you interact, the LLM’s primary job is to understand your intent and extract structured data into predefined slots like customer_id, last_inquiry_type, and account_selection.
High-Speed Cache: At the start of your conversation, your entire 20 KB JSON profile is loaded from a traditional database (MongoDB) into an in-memory cache (Redis). This makes data access nearly instantaneous.
Predefined Flow: When you ask about the "large purchase," the system recognizes the intent query_transaction_history. A predefined flow knows this intent requires the customer_id and account_number slots.
Precise Query: It pulls these values from Redis and makes a highly efficient, targeted query to the main transaction database.
Clean Prompt: The LLM receives a minimal, clean prompt containing only your question and the specific transaction data it needs to form an answer.
Persist and Offload: At the end of the session, the updated 20 KB JSON profile is written back to MongoDB, and the full conversation transcript (for audit purposes) is offloaded to inexpensive cloud storage like Amazon S3.
The Dramatic Cost Difference
This architecture avoids the high cost of a massive, always-on vector index. The costs for standard databases and caches are negligible in comparison.
Head-to-Head: The Final Comparison
Cost Savings: A Game-Changer
Choosing the Sentia structured data approach results in massive savings, freeing up capital to invest in better AI models and features.
vs. Single-Cluster: ~90% savings at medium volume.
vs. Physical Separation: ~99% savings.
Performance: Speed and Latency
In the world of user experience, every millisecond counts. Latency is the wait time for a single response, while throughput (speed) is how many users the system can handle concurrently.
Latency Reduction: The Sentia architecture is estimated to have 30-50% lower latency per interaction. This is because reading from Redis is faster than a complex vector search, and smaller prompts are processed much more quickly by the LLM.
Speed/Throughput Improvement: For the same hardware cost, the Sentia architecture can handle 2x to 3x higher throughput (more concurrent conversations) because each request is less computationally intensive.
Conclusion: The Right Tool for the Right Job
The AI revolution in banking is real, but it doesn’t require throwing out decades of robust software engineering principles. For use cases that rely on structured customer data—which defines nearly all of banking—a brute-force semantic search approach is a slow, inefficient, and incredibly expensive choice.
By embracing a structured data model, where memory is a clean, organized profile and LLMs are used to intelligently interact with it, institutions can build AI assistants that are not only smarter and faster but are also economically viable at scale. It’s a reminder that the future of AI isn’t just about powerful models; it’s about the elegant and efficient architecture that surrounds them.
The architectural choices made today will define the profitability and performance of your AI initiatives for the next decade. The Sentia platform demonstrates that a return to robust, structured data principles can deliver a stateful AI experience that is not only superior in performance but is also an order of magnitude more cost-effective.
Augmen.io
5th Floor, SINE IIT Bombay, Powai, Mumbai, India. 400076
Contact us -
contact@augmen.io
+91 9717067973
© 2025. All rights reserved.
Paaw innovations Private Limited
Quick Links -